Topic: Question about hashes in QElectroTech
An die Haupt-Entwickler:
Salut Joshua !
Salut Laurent !
English follows below!
Brauchen wir bei QET zufällige Hashes, die irgendwas verschlüsseln, oder so? Die einzigen zufälligen Zahlen, die ich sehe, sind die UUIDs in den Elementen. Aber vielleicht übersehe ich auch etwas...
Grund der Frage:
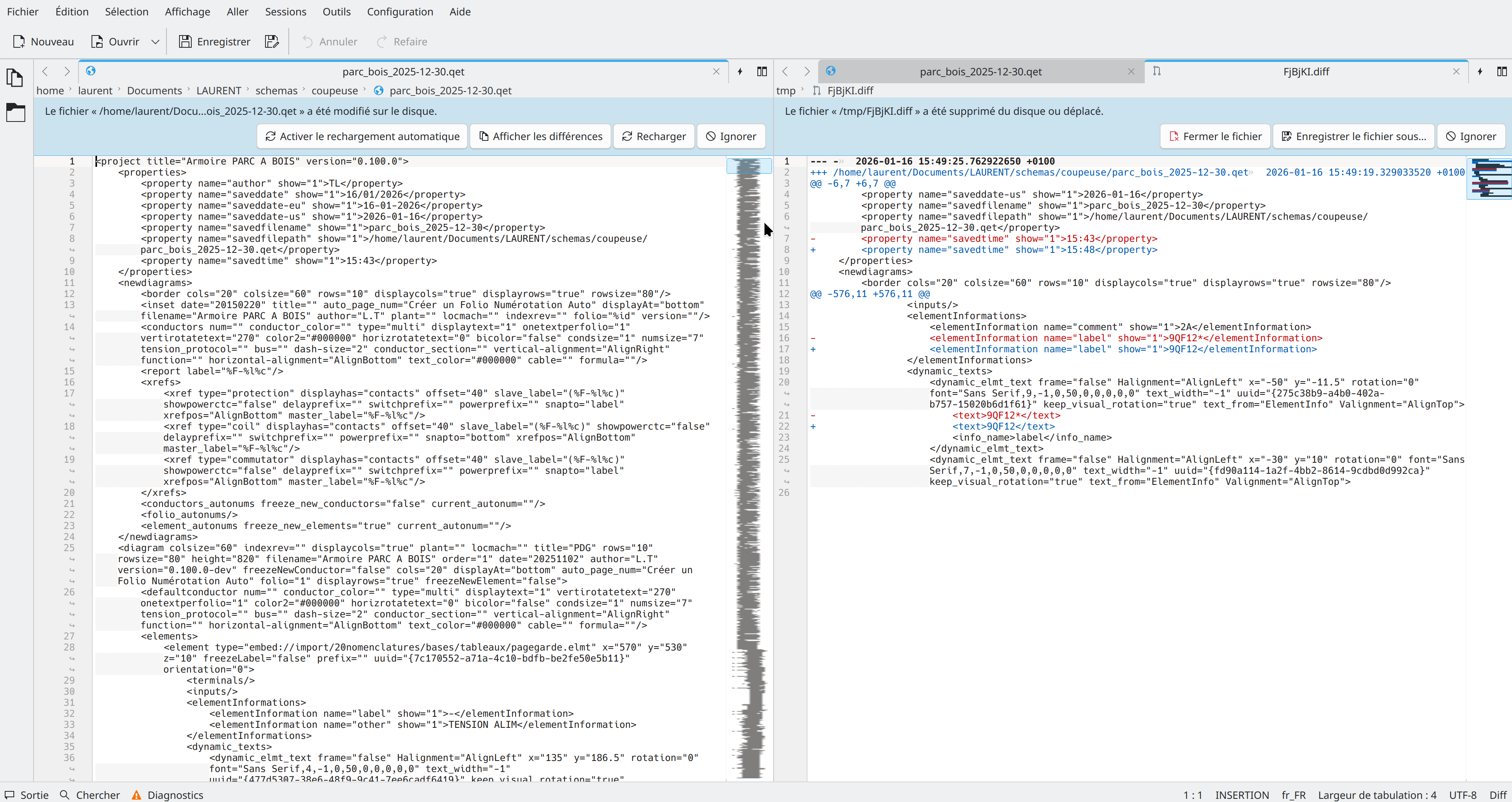
Die XML-Tags in den Element- und Projekt-Dateien werden bei jedem Abspeichern durcheinandergewürfelt, da die Informationen dazu in Hashes gespeichert werden, deren zugrundeliegende Zufallszahl regelmäßig erneuert wird.
Wenn wir auf die zufällige Sortierung in den Hashes verzichten können, können wir dafür beim Start von QET einen Vorgabewert an Qt geben, sodass die Sortierung der XML-Tags von einem Speichervorgang zum nächsten nicht komplett durcheinandergewürfelt werden!
Bei Projektdateien wird das XML regelmäßig aus der internen SQlite-DB neu erzeugt, und daher sind die Tags nicht immer in derselben Reihenfolge.
Bei Element-Dateien scheint es aber sehr gut zu funktionieren, dass die Tags nicht gemischt werden, wenn die Randomisierung abgeschaltet ist! Auf diese Art werden DIFFs von Element-Dateien nicht so groß, wenn nur eine Kleinigkeit daran geändert wird, wie z.B. das Hinzufügen einer weiteren Sprache.
Einen Patch habe ich in meinem github-repository vorbereitet.
Gruß
plc-user
English translation:
To the main-developers:
Do we need random hashes with QET that encrypt something or something like that? The only random numbers I see are the UUIDs in the elements. But maybe I'm overlooking something...
Reason for the question:
The XML tags in the element and project files are mixed up every time they are saved, because the information is stored in hashes whose underlying random number is regularly renewed.
If we can do without the random sorting in the hashes, we can give Qt a default value when starting QET so that the sorting of the XML tags is not completely mixed up from one save operation to the next!
For project files, the XML is regularly regenerated from the internal SQlite DB, so the tags are not always in the same order.
However, for element files, it seems to work very well that the tags are not mixed when randomization is turned off! This way, DIFFs of element files do not become so large when only a small change is made, such as adding another language.
I prepared a patch in my github-repository.
Best regards,
plc-user