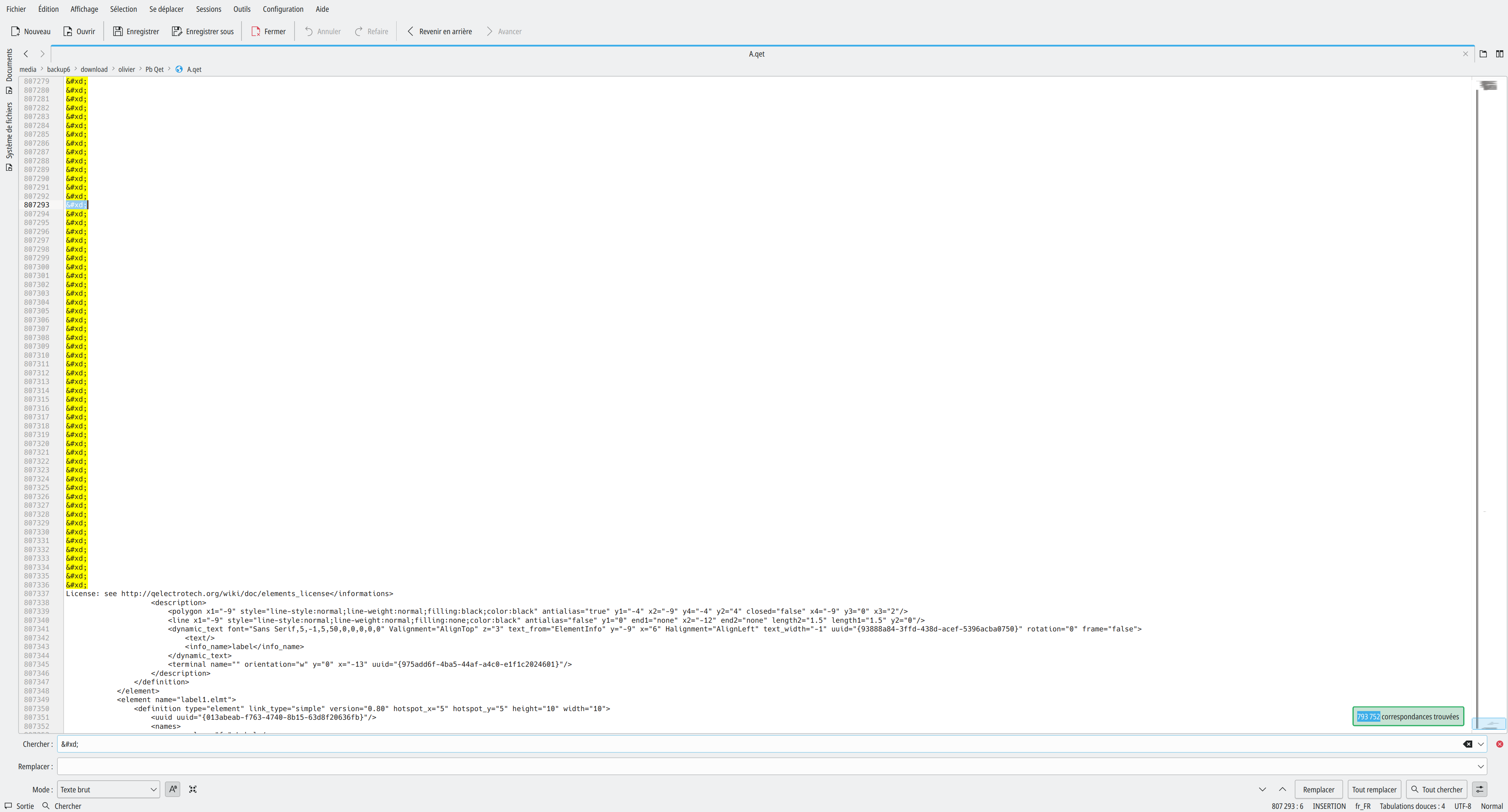
Re: Ouverture du projet exssivement longue ...
wc -m 
 < A.qet
[2] 7651D’après wc tu as 7651 X ton Carriage return :
, donc 7651 lignes sur 807418 lignes que contient ton fichier XML:
wc -l < A.qet
807418http://www.man-linux-magique.net/man1/wc.html
Avec les outils gnu sur linux tu as de quoi toi faire si tu sais lire les man et faire des recherches sur la toile, oublie Wind*@... juste livré avec une calculette et un bloc-note ... ![]() c'est pas demain que l'os de Redmond ira sur les supers calculateurs ou dans l'espace ...
c'est pas demain que l'os de Redmond ira sur les supers calculateurs ou dans l'espace ... ![]()
"Le jour où tu découvres le Libre, tu sais que tu ne pourras jamais plus revenir en arrière..."Questions regarding QET belong in this forum and will NOT be answered via PM! – Les questions concernant QET doivent être posées sur ce forum et ne seront pas traitées par MP !